
CASE STUDY
How can we trust the algorithms that we now count on in our daily lives?
MATILDA Logo
PEOPLE

Professor Kate Smith-Miles
We humans are naturally suspicious creatures.
But when it comes to our phones and computers, we seem to be very trusting. If our map app on our mobile phone gives us directions somewhere, or our computer gives us search results to a question we ask, we tend to trust those results.
It’s not a human, though, giving those results. It’s an algorithm.
The role of algorithms in our lives is growing rapidly, from simply suggesting new friends on social media, to more critical matters in business, health care, and government. But how do we know we can trust an algorithm’s decision?
In June 2019, more than 100 people learned the hard way that sometimes algorithms can get it very wrong. Google Maps got them all stuck on a muddy private road in a failed detour to escape a traffic jam heading to Denver International Airport.
“As our society becomes increasingly dependent on algorithms for advice and decision making, it is concerning that we haven’t yet tackled the critical issue of how we can trust them,” says Professor Kate Smith-Miles, an ACEMS Chief Investigator at The University of Melbourne.
The good news is that Kate is tackling that issue, and already has a solution that is up and running. Kate is the leader of a team that has developed a new web-based platform that really tests algorithms.
WHAT IS AN ALGORITHM?
Algorithms are nothing more than computer programs that make decisions based on a set of rules: either rules that we have told them, or rules that they have figured out themselves based on examples we have given them. In both cases, humans are in control of these algorithms and how they learn and are tested. So if algorithms are flawed in some way, it is our doing.
“The whole issue of whether we can trust algorithms isn’t about the algorithms themselves. It’s really about how we test them,” says Kate.
Her web-based platform is called MATILDA, which stands for the Melbourne Algorithm Test Instance Library with Data Analytics. Kate says MATILDA ‘stress-tests’ algorithms, and shows their objective strengths and weaknesses through powerful visualisations of a comprehensive 2D test “instance space”.
Kate says the problems with testing algorithms start with the academic practice, where most algorithms are typically tested on a set of benchmark test cases that aren’t necessarily unbiased, challenging, or even realistic. Also, the results of these tests on algorithms tend to report only how they perform ‘on average’, rather than trying to identify the conditions when they may fail.
"If a new algorithm is superior on these benchmarks on average, it is usually publishable. If an algorithm is not competitive with existing algorithms, it is either hidden away or some new test examples are presented where the algorithm is superior," says Kate.
“It’s the computer science version of medical researchers failing to publish the full results of clinical trials, and the standard academic peer review process encourages this culture.”
All algorithms have weaknesses, or warts, as Kate likes to call them. She says it's extremely important to show where an algorithm will work well, and more importantly, where it could be unreliable. That’s exactly what MATILDA does.
"These instance spaces are filled with carefully generated test examples to augment benchmark datasets, and cover every nook and cranny of the space in which the algorithm could operate: be that working out when it is safe for a plane to land, or ensuring cancer diagnosis is accurate. They reveal which algorithms should be used when, and why," says Kate.
Kate hopes her ’instance space analysis’ will soon replace the standard ‘on average' reporting, now that the tools are available to support a more insightful approach.
Despite Kate’s MATILDA solution to testing algorithms, the whole issue of gaining human trust is of course a bit more complicated.
“A software developer once told me that if their algorithm solves a problem too quickly, the client sometimes doesn’t trust the result. So their solution was to artificially slow down the algorithm so it appeared to be working harder to arrive at the same answer,” says Kate.
So it seems that trust of some humans is not always earned by rigorous statistical analysis or mathematical proof. But it can sure go a long way, though.
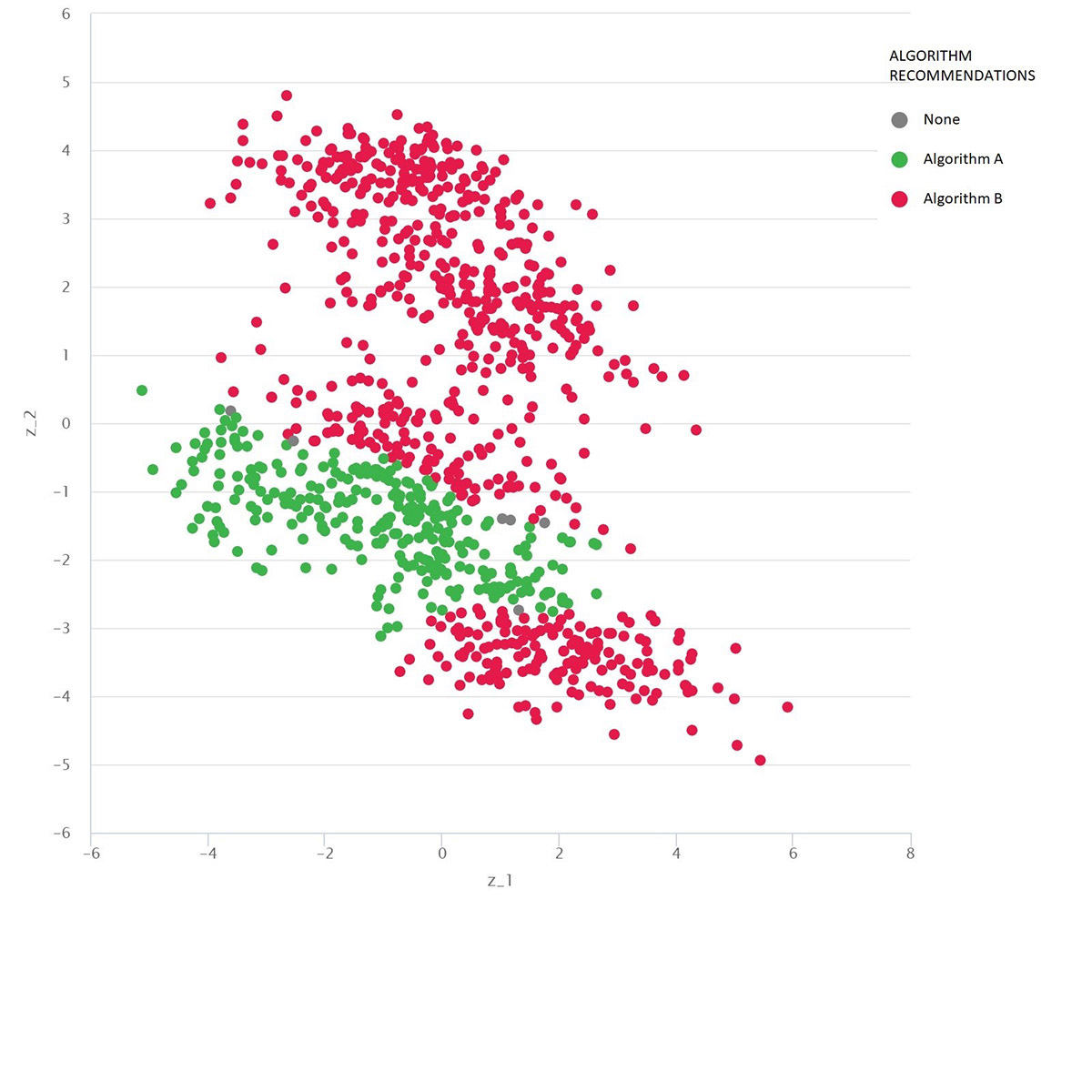
A Google-maps-type problem with diverse test scenarios as dots: Algorithm B (red) is best on average, but Algorithm A (green) is better in many cases. Source: MATILDA